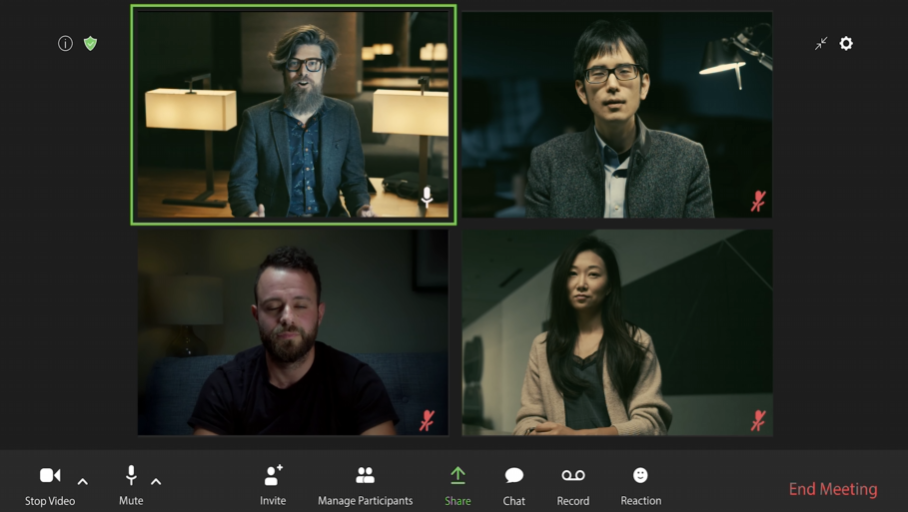
Nvidia has released a demo of a new AI system that generates a video conferencing stream from a single still 2D image.
The new feature, called Vid2Vid Cameo, was announced back in December 2020. It works on a deep learning model built on a 180,000+ video data set model trained to identify 20 key points that encode the placement of your facial features, including the mouth, eyes, and nose.
According to Nvidia, Vid2Vid Cameo will soon be available in the Nvidia Video Codec SDK and Nvidia Maxine SDK as “AI Face Codec.”
To work, the feature needs two inputs, a source image and a live webcam feed. Vid2Vid overlays the person’s gestures, motions and expressions onto the still image supplied, converting it into a life-like animation of a person speaking.
Simply speaking, you can be as dishevelled as a Golden Retriever that zoomied in mud and yet, look as presentable and professional as possible during the video call.
But the software has a different function too. According to Nvidia, Vid2Vid Cameo will also assist with addressing one of the most vexing difficulties that individuals have encountered throughout the pandemic: choppy and low-resolution video streams.
Instead of sending huge video streams between video conferencing users, this technology sends voice data and information on facial movement. The data is subsequently synthesized into a talking-head video on the receiver’s side, allowing meetings to run smoothly and without delay.
Vid2Vid Cameo will soon be available on Nvidia Video Codec SDK and Nvidia Maxine SDK but if you don’t want to wait, check out this demo.
To learn more about Vid2Vid Cameo, click here.
Image credit: Nvidia
Source: Nvidia
MobileSyrup may earn a commission from purchases made via our links, which helps fund the journalism we provide free on our website. These links do not influence our editorial content. Support us here.
